- 調査・研究
人工知能による画像認識で業務効率化にトライ②
前記事「人工知能による画像認識で業務効率化にトライ①」の続きです。
前回の内容を簡単にまとめると、
スキャナで読み込んだ書類の画像を人工知能(ディープラーニング)の画像認識を使い、取引先や書類の種類などを判断し、書類の仕分けや台帳への転記を自動化することで契約管理部門の作業効率化に寄与することを目的にシステム化のチャレンジをしています。
このためには大きく以下の内容をクリアする必要があります。
①過去の書類を使い人工知能で学習モデルを作成する
②認識させたい画像ファイルを学習済の人工知能に読ませて、格納先を確定する
③画像ファイルを確定したフォルダに自動で移動する
④移動させる際に、台帳(Excel)に取引先名や書類名を自動で転記する
⑤画像ファイルから 契約名・契約番号等を取得し、台帳(Excel)に追記する
そこで今回は上記のうち
「①過去の書類を使って人工知能で学習モデルを作成する」
「②認識させたい画像ファイルを学習済の人工知能に読ませて、格納先を確定する」
にチャレンジしました。
学習させる
①学習用の画像を格納
書類の種類(基本契約書、個別契約書、注文書、検収書)ごとにフォルダを用意し、画像を格納します。画像認識の精度を上げるためには大量の画像が必要になるので、各書類ごとに 元の画像を少し傾けたり、色をつけたり、ぼやかしたりして加工し、画像の数を増やしました。今回は1書類につき100枚の 学習用の画像を準備しました。(書類の画像は1ページのみです)

(画像をクリックすると拡大します)
②格納した画像を学習
続いて以下のプログラムを実行して格納した画像を全て学習させます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
*学習用のソース(pythonです)************************************************ # -*- coding: utf-8 -*- #!/usr/bin/env python import argparse import cPickle import numpy as np import six import cv2 import os import six.moves.cPickle as pickle import chainer from chainer import computational_graph as c from chainer import cuda import chainer.functions as F from chainer import optimizers parser = argparse.ArgumentParser(description='Training Program') parser.add_argument('--gpu', '-g', default=-1, type=int, help='GPU ID (negative value indicates CPU)') parser.add_argument('--model', '-m', default=0, help ='Trained Model') args = parser.parse_args() batsize = 20 i_epoch = 10 otherNo = 100 faceNo = 100 xTrain = [] xTest = [] yTrain = [] yTest = [] for i in range(0,4): image = os.listdir('./'+str(i)) if i == 0: imageNo = otherNo else: imageNo = faceNo for j in range(len(image)): if j == imageNo: break if image[j].find('.png') > 0 or image[j].find('.jpg') > 0 or image[j].find('.jpeg') > 0: #ラスト30枚はテストデータ if imageNo - j > 30: xTrain.append(cv2.imread('./'+str(i)+'/'+image[j])) yTrain.append(i) else: xTest.append(cv2.imread('./'+str(i)+'/'+image[j])) yTest.append(i) #print('yTrain=',yTrain) #読み込んだデータを0~1に正規化,numpy.arrayに変換 xTrain = np.array(xTrain).astype(np.float32).reshape((len(xTrain),3, 150, 200)) / 255 yTrain = np.array(yTrain).astype(np.int32) xTest = np.array(xTest).astype(np.float32).reshape((len(xTest),3, 150, 200)) / 255 yTest = np.array(yTest).astype(np.int32) N = len(yTrain) N_test = len(yTest) # モデルの設定 or 保存されたモデルの読み込み if args.model != 0: if args.gpu >= 0: cuda.init(args.gpu) model = pickle.load(open(args.model,'rb')) else: # ニューラルネットワークの定義。 model = chainer.FunctionSet(conv1= F.Convolution2D(3, 8, 5,stride=2,pad=2), conv2= F.Convolution2D(8, 16, 5,stride=2,pad=2), l3= F.Linear(2240, 1120), l4= F.Linear(1120, 4)) if args.gpu >= 0: cuda.init(args.gpu) model.to_gpu() # 伝播の設定 def forward(x_data, y_data, train=True): x, t = chainer.Variable(x_data, volatile=not train), chainer.Variable(y_data, volatile=not train) h = F.max_pooling_2d(F.relu(model.conv1(x)), ksize = 5, stride = 2, pad =2) h = F.max_pooling_2d(F.relu(model.conv2(h)), ksize = 5, stride = 2, pad =2) h = F.dropout(F.relu(model.l3(h)), train=train) y = model.l4(h) return F.softmax_cross_entropy(y, t), F.accuracy(y, t) # オプティマイザーの設定 optimizer = optimizers.Adam() optimizer.setup(model.collect_parameters()) # 学習のループ for epoch in six.moves.range(1, i_epoch + 1): print('epoch', epoch) # 学習 perm = np.random.permutation(N) sum_accuracy = 0 sum_loss = 0 for i in six.moves.range(0, N, batsize): x_batch = xTrain[perm[i:i + batsize]] y_batch = yTrain[perm[i:i + batsize]] if args.gpu >= 0: x_batch = cuda.to_gpu(x_batch) y_batch = cuda.to_gpu(y_batch) optimizer.zero_grads() loss, acc = forward(x_batch, y_batch) loss.backward() optimizer.update() if epoch == 1 and i == 0: with open("graph.dot", "w") as o: o.write(c.build_computational_graph((loss, )).dump()) with open("graph.wo_split.dot", "w") as o: g = c.build_computational_graph((loss, ), remove_split=True) o.write(g.dump()) print('graph generated') sum_loss += float(cuda.to_cpu(loss.data)) * len(y_batch) sum_accuracy += float(cuda.to_cpu(acc.data)) * len(y_batch) print('train mean loss={}, accuracy={}'.format( sum_loss / N, sum_accuracy / N)) # テスト sum_accuracy = 0 sum_loss = 0 for i in six.moves.range(0, N_test, batsize): x_batch = xTest[i:i + batsize] y_batch = yTest[i:i + batsize] if args.gpu >= 0: x_batch = cuda.to_gpu(x_batch) y_batch = cuda.to_gpu(y_batch) loss, acc = forward(x_batch, y_batch, train=False) sum_loss += float(cuda.to_cpu(loss.data)) * len(y_batch) sum_accuracy += float(cuda.to_cpu(acc.data)) * len(y_batch) print('test mean loss={}, accuracy={}'.format( sum_loss / N_test, sum_accuracy / N_test)) #モデルの保存 pickle.dump(model, open('model'+str(epoch), 'wb'),-1) |
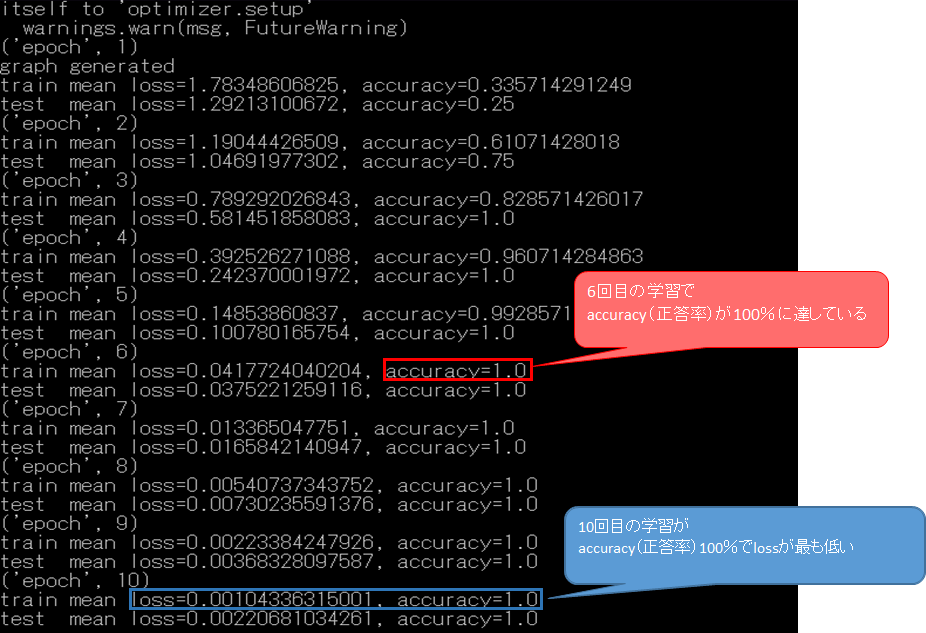
学習過程は以下のように確認できます。
epoch:学習回数
train mean loss:「学習時のモデル」と「書類画像」の誤差を積み上げた数字。値が低いほど精度が高い。
train mean accuracy:「正答率」100%に近いほど正解に近い。
(画像をクリックすると拡大します)
今回は学習を10回行い、6回目の学習で既にaccuracy(正答率)が100%に収束しました。accuracyが100%でlossが一番低い10回目の学習モデルが最も精度が高いので、この10回目のモデル(model10)を使って画像認識をさせようと思います。
※学習モデルの結果(1回~10回)はバイナリーファイル(model1~model10)として作成されます。
認識させる
以下のプログラムを実行して、実際の書類の画像(基本契約書)を認識させてみます。
※プログラムに使う学習モデル(model10)を定義して実行します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
*********************************************************************** # -*- coding: utf-8 -*- #!/usr/bin/env python import sys import cPickle import numpy as np import six import cv2 import os import six.moves.cPickle as pickle import chainer from chainer import computational_graph as c from chainer import cuda import chainer.functions as F from chainer import optimizers # ここで学習モデルを定義 model = pickle.load(open('model10','rb')) chara_name = ['keiyaku-0', 'keiyauku-1','keiyaku-2','keiyaku-3'] face_aaa = cv2.imread(sys.argv[1]) img = [] img.append(face_aaa) face_image = np.array(img).astype(np.float32).reshape((len(img),3, 150, 200))/ 255 x = chainer.Variable(face_image, volatile=False) h = F.max_pooling_2d(F.relu(model.conv1(x)), ksize = 5, stride = 2, pad =2) h = F.max_pooling_2d(F.relu(model.conv2(h)), ksize = 5, stride = 2, pad =2) h = F.dropout(F.relu(model.l3(h)), train=False) y = model.l4(h) count= 0 result_data = cuda.to_cpu(y.data[count]) recognized_class = chara_name[result_data.argmax()] print ('prob = ' , result_data) print ('answer = ',recognized_class) *************************************************************************************** |
認識結果は以下の通りです。

(画像をクリックすると拡大します)
①認識させる画像名(0.jpg)
②1つ目のフォルダ(「基本契約書」を学習させたフォルダ)との類似度(6.12865877)
③2つ目のフォルダ(「個別契約書」を学習させたフォルダ)との類似度 (-3.29494834)
④3つ目のフォルダ(「注文書」を学習させたフォルダ)との類似度 (-2.46448469)
⑤4つ目のフォルダ(「契約書」を学習させたフォルダ)との類似度 (-2.60804892)
認識結果は、1つ目のフォルダとの類似度が一番高いので1つ目のフォルダを正解とします。認識させた画像は「基本契約書」の画像なので認識結果は正しいことが分かります。試しに、「基本契約書」に落書きをした画像(3-1.jpg、3-2.jpg)を認識させてみましたが、問題なく認識できました。これくらいの違いがあっても、認識してくれるようです。
3-1.jpg 3-2.jpg


参考までに、一番精度の低い学習モデル(model1)でも同じことをして見ましたが、model10と比べると類似度が低かった(0.07245407)です。

(画像をクリックすると拡大します)
これで、書類画像の学習と分類(格納先の確定)ができることは確認できました。画像ファイルの移動も格納先が確定したので、ファイル操作は容易だと考えます。
契約管理部門のもう一つの要望は、分類した画像から契約名や契約番号などの文字を取得して、台帳(Excel)への転記を自動的に行うことです。画像から文字を認識するのは 画像認識ではなくOCR機能になるので、画像認識についての検証はここまでにして、今後はOCR機能の検証にトライしてみたいと思います。